东京摩天楼上的孤独军团
1983年8月,一位《时代周刊》记者走进东京市中心一座摩天大楼的21层,他看到的是一间宽敞明亮的研究室,三十六名计算机科学家每天在这里工作长达十六个小时,他们的目光穿透终端屏幕,凝视着十年后的未来。房间的主人、四十七岁的电子工程师渊一博刚刚获得日本政府四亿五千万美元的承诺——这在当时是史上最大规模的计算机研究投资。他的使命只有一个:让日本在计算机领域跃升一步,创造全新的超级机器,专门用于那个被称为人工智能的神秘分支。
直到此刻,计算机领域的开创性工作几乎完全由欧美科学家垄断。过去二十五年间,麻省理工学院、斯坦福大学、卡内基梅隆大学和爱丁堡大学的AI实验室先后推出了文字处理、电子游戏、分时系统、机器人控制和先进导弹制导系统。现在,日本要将追赶者身份抛诸脑后,在十年内跻身这一新兴知识产业的全球领导者之列。这个被命名为第五代计算机系统的计划,承载着一个民族超越西方技术霸权的终极野心。
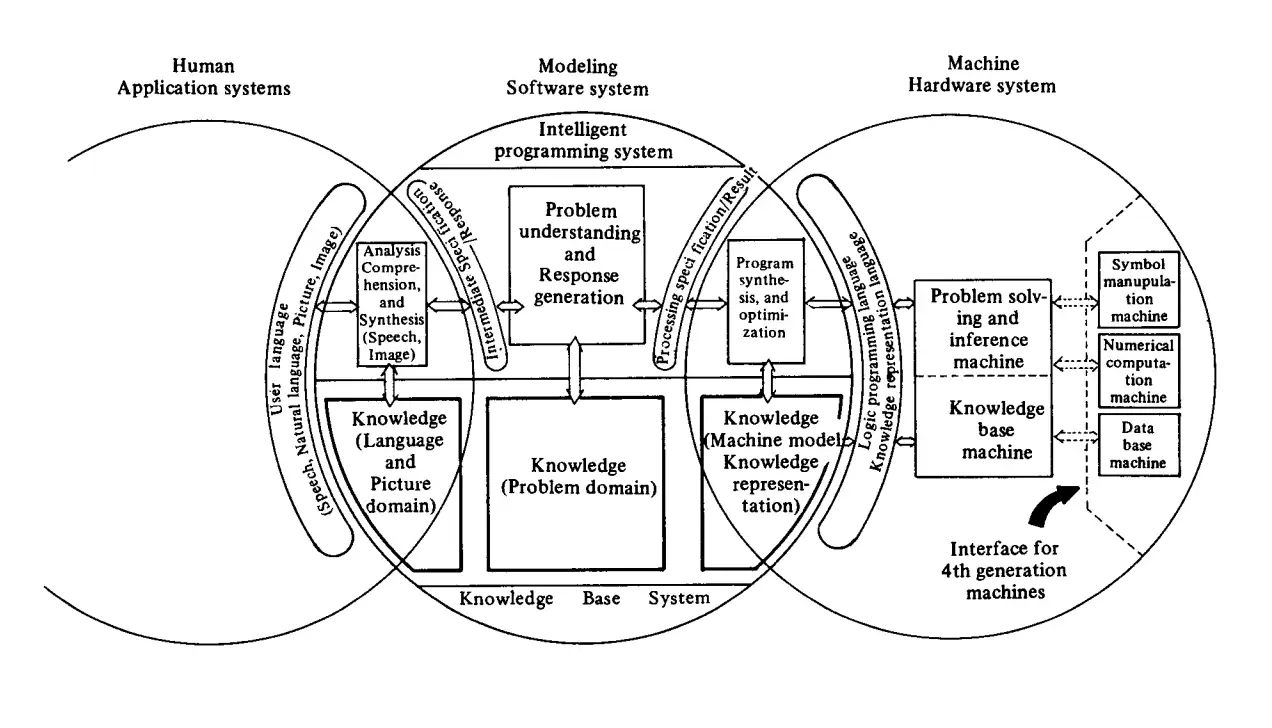
计算机发展史上的代际划分向来以核心组件的技术进步为标志。第一代依赖真空管,第二代采用晶体管,第三代引入集成电路,第四代——刚刚浮现——依赖超大规模集成电路(VLSI),芯片密度之高,必须由另一台计算机来设计。第五代将把大量VLSI芯片以并行方式排列,为速度和功率的突破性飞跃扫清道路。更重要的是,这些计算机将不再局限于处理数学数据,而是开始执行类人推理:发现模式、做出假设、进行推断、得出结论。一种名为Prolog的编程语言将成为其核心,机器内部将存储复杂的知识目录,囊括人类解决棘手问题时使用的经验法则和思维捷径。
渊一博站在这个宏大构想的核心。二十年前,他因不满日本电子技术研究所僵化的体制,曾愤然离职两周——这种张扬的个性在日本极为罕见,却为他赢得了同侪的钦佩。斯坦福大学计算机科学教授爱德华·费根鲍姆称他为"东方几乎闻所未闻的那种人——仅凭意志力就能凭空创造奇迹的人"。
从模仿者到开拓者
日本计算机产业在1970年代末面临着深刻的存在危机。过去三十年,这个岛国凭借惊人的制造能力在钢铁、汽车和消费电子领域横扫全球,但在计算机这一最具战略意义的新兴领域,日本始终扮演着追随者的角色。美国IBM公司的系统架构定义了行业标准,英特尔和摩托罗拉的芯片设定了技术路线,日本的计算机公司只能在价格和可靠性上做文章。
1979年,日本电子技术综合研究所(ETL)的一群科学家开始思考这个问题。他们注意到一个重要趋势:计算机应用正在从数值计算向知识信息处理转变。未来的计算机需要处理文本、语音、图像等非数值数据,需要理解自然语言,需要从海量数据中提取知识并进行推理。这些功能在传统冯·诺依曼架构下效率低下——因为传统计算机是为数值计算设计的,而不是为符号推理设计的。
东京大学元冈教授成为这一愿景的代言人。1981年10月,在他的主持下,国际第五代计算机系统会议在东京召开。这次会议的规格令人印象深刻:来自全球的顶尖计算机科学家齐聚一堂,聆听日本方面提出的宏大计划。美国方面的代表们震惊地发现,日本不仅仅是想追赶,而是要完全绕过美国,开辟一条全新的技术道路。
会议上展示的愿景令人窒息:到1990年代,计算机将能够通过语音、图像和自然语言与人类自由交流,能够在数秒内翻译十万字的日语文本,能够理解并回答专业领域的复杂问题,能够从海量知识库中自动推理出解决方案。这些功能在当时看来如同科幻小说,但日本人给出了详细的十年路线图和巨额预算。
1982年4月,新一代计算机技术研究所(ICOT)在东京成立。这个机构的运作方式在日本研究体系中前所未有:它不是某个大学的附属机构,也不是某个企业的研发部门,而是由通产省直接资助的独立研究所,拥有完全的自主权来制定研究议程。渊一博被任命为研究中心主任,他从日本八大计算机公司(富士通、日立、三菱电机、NEC、冲电气、东芝、松下和夏普)各抽调八名年轻研究员,组成了约一百人的核心团队。

冯·诺依曼的阴影
要理解第五代计算机的革命性,必须先理解传统计算机的局限性。1945年,数学家约翰·冯·诺依曼提出了著名的存储程序概念:计算机由运算器、控制器、存储器、输入设备和输出设备五部分组成,程序和数据存储在同一存储器中,指令按顺序逐条执行。这一架构统治了计算机世界四十余年,至今仍是主流PC、服务器和智能手机的基础。
但冯·诺依曼架构有一个致命缺陷:它天生适合数值计算,却拙于符号处理。当你让一台传统计算机执行简单的逻辑推理任务时——比如从"所有人都会死"和"苏格拉底是人"推导出"苏格拉底会死"——它的效率低得惊人。因为传统计算机是按顺序执行指令的,而逻辑推理本质上是并行的:大脑可以同时考虑多个假设、多个路径、多种可能性。
日本科学家提出的解决方案是大胆的:放弃冯·诺依曼架构,设计全新的并行推理机器。这种机器将采用数百甚至数千个处理器并行工作,每个处理器专门优化用于逻辑推理而非算术运算。在这种架构下,Prolog——一种基于一阶谓词逻辑的编程语言——将成为机器的"母语",就像C语言之于传统计算机。
Prolog的独特之处在于其声明式编程范式。程序员不需要告诉计算机如何一步步完成任务,只需要描述问题的逻辑关系,计算机会自动搜索解决方案。这种范式与人工智能的需求天然契合:专家系统、自然语言理解、机器翻译——所有这些应用的核心都是逻辑推理和模式匹配,而非数值计算。
但Prolog有一个致命的性能问题:它的执行机制依赖于深度优先搜索和回溯,这在大规模应用中会导致指数级的计算复杂度。当问题规模增大时,即使是最高效的Prolog实现也会变得难以忍受地缓慢。日本人的赌注是:通过硬件层面的并行化来解决这个问题。如果一台机器能同时探索成千上万条推理路径,那么单条路径上的回溯开销就不再是致命障碍。
PSI:第一个推理引擎
1982年至1984年的初始阶段,ICOT团队专注于基础技术的开发。他们的第一个成果是ESP(Extended Self-contained Prolog)——一种扩展的顺序逻辑编程语言,在标准Prolog的基础上增加了协程构造、非局部切割等系统编程必需的功能。紧接着是PSI(Personal Sequential Inference Machine)——世界上第一台将硬件推理引擎纳入个人工作站的机器。
PSI的设计目标是一个令人惊讶的转折。最初的计划是建造大型机规模的推理系统,但渊一博决定改变方向:先开发个人工作站级别的推理机,让研究人员在自己的办公桌上就能进行逻辑编程。这个决定背后有着深思熟虑的战略考量:只有让足够多的人使用和改进这套技术,才能积累足够的经验来设计更强大的系统。
PSI的技术规格在当时相当惊人:40位字长,16兆字的最大主存容量(在1983年这是天文数字),硬件支持的堆栈式存储管理,以及专门为Prolog执行优化的微指令集。它的目标执行速度是每秒两万到三万次逻辑推理(LIPS)。作为对比,当时最快的商用Prolog系统只能达到每秒几千LIPS。
但PSI最大的创新在于其软件生态。SIMPOS(Sequential Inference Machine Programming and Operating System)是世界上第一个完全基于逻辑编程语言的操作系统——从内核到文件系统,从设备驱动到用户界面,全部用ESP写成。这证明了逻辑编程不仅是一种"玩具语言",而足以支撑复杂系统的开发。
数百台PSI机器被制造出来,部署在ICOT和各协作机构。机器甚至被推向商业市场——尽管价格高昂,但仍有一定销量。PSI的成功给了ICOT团队信心:他们证明了自己的技术路线是可行的。

并行的深渊
1985年至1988年的中间阶段,项目的重心转向并行化。这是一个技术上的险棋。并行计算在1980年代中期仍处于婴儿期:没有人真正知道如何有效地编程并行机器,没有人知道什么样的硬件架构最适合符号处理,甚至没有人知道并行逻辑编程的理论基础是否稳固。
ICOT团队的解决方案是一整套全新的技术栈。首先是GHC(Guarded Horn Clauses)——一种全新的并行逻辑语言,后来演变为KL1。与传统的顺序Prolog不同,KL1允许程序员显式地表达并行性,同时避免了传统并行语言中的竞争条件和死锁问题。它的设计哲学是"不要共享状态,通过消息传递通信"——这一理念在几十年后将成为主流分布式系统的基石。
硬件方面,Multi-PSI作为第一代并行推理实验平台诞生。它将64台PSI-II处理器以二维网格的方式连接起来,运行KL1程序。这是一个极其昂贵的实验——每台PSI-II的造价都在数万美元以上——但它为真正的并行推理机器积累了宝贵经验。
与此同时,ICOT开始设计PIM(Parallel Inference Machine)系列。PIM的架构模型是一个松散耦合的网络,连接着若干紧密耦合的处理器集群。每个集群本质上是一台共享内存的多处理器系统,集群之间通过高速网络互联。这种层次化架构的设计目标是:在保持编程模型简洁的同时,最大限度地利用硬件并行性。
PIM的设计参数令人瞠目:最初的规划是1000个处理单元,后来调整为多种规格。PIM/p采用512个处理器,PIM/m采用256个处理器,还有更小的实验型号。每个处理单元都经过专门优化,用于执行KL1语言的核心操作。整个系统的峰值性能目标是每秒一亿到十亿次逻辑推理(100-1000 MLIPS)。
硅谷的恐慌
日本第五代计算机计划在国际上引发的反应,远远超出了技术讨论的范畴。在华盛顿和硅谷,这个计划被视为对西方技术霸权的直接挑战——有人甚至称之为"AI珍珠港"。
斯坦福大学教授爱德华·费根鲍姆和科学作家帕梅拉·麦考杜克在1983年出版的《第五代:人工智能与日本对世界的计算机挑战》一书中敲响了警钟。这本书的开篇直言不讳:“日本人威胁要颠覆美国的主导地位,通过在其他国家的游戏中击败它们来扰乱经济秩序。”

费根鲍姆的担忧并非空穴来风。作为专家系统技术的开创者之一,他深知AI技术的战略价值。他在美国国会作证时的证词引发了广泛影响:“美国正以每天一天的速度挥霍着它的领先优势。”
美国的反应是迅速而激烈的。1983年9月,微电子与计算机技术公司(MCC)在德克萨斯州奥斯汀成立。这是一个由十三家美国科技公司组成的营利性产业联盟,年度预算超过一亿美元,目标是追赶日本的第五代计划。MCC的研究方向涵盖半导体技术、计算机辅助设计、人工智能和高级软件技术,其规模之大前所未有。
与此同时,美国国防部高级研究计划局(DARPA)启动了战略计算计划,承诺每年投入高达九千五百万美元用于"新一代"计算机的军事应用。这个计划的焦点之一——讽刺的是——正是自主车辆导航,一个至今仍未完全解决的技术难题。
欧洲同样感受到了压力。英国启动了阿尔维计划,投入约十亿英镑用于信息技术研究。欧共体推出了ESPRIT计划,投资规模与前者相当。整个西方世界仿佛被日本的挑战惊醒,纷纷将AI和先进计算列为国家战略优先级。
但在这股恐慌浪潮之下,一些冷静的声音开始浮现。美国计算机科学家们注意到,日本的计划存在一些根本性的问题:逻辑编程的效率瓶颈是否真的能通过硬件并行化解决?专用的推理机器能否跟上通用处理器的性能提升速度?自然语言处理和语音识别的技术难题是否仅仅通过更快的硬件就能攻克?
机器的黄昏
1989年至1992年的最终阶段,ICOT团队将之前开发的所有技术整合为完整的原型系统。PIM系列并行推理机器终于成形,PIMOS操作系统趋于成熟,KAPPA-p并行数据库管理系统投入使用,大量应用软件被开发出来以验证系统的实用性。
1992年6月1日至5日,第五届第五代计算机系统国际会议在东京召开。这是项目的收官之作,也是ICOT团队向世界展示十年成果的舞台。会议的技术演示令人印象深刻:从分子生物学到法律推理,从电路设计到蛋白质序列分析,一系列复杂应用在PIM机器上展示了近乎线性的并行加速效果。
但与会的国际观察者们很快发现了一个尴尬的事实:这些演示虽然技术精湛,却缺乏现实世界的应用场景。一个并行法律推理系统可以高效地处理案例库,但谁来输入那些案例?谁来维护知识库?谁来使用这些输出?这些问题在演示中被巧妙地回避了。
更深层的危机在于技术路线的失效。1982年,当项目启动时,Prolog和Lisp被认为是AI的两大支柱语言。但到1992年,情况已经完全不同:面向对象编程范式崛起,C++成为系统开发的主流语言,Unix操作系统统治服务器市场,PC革命正在改变一切。日本的专用推理机器在这个新世界里找不到自己的位置。
PSI机器的造价高达数万美元,而一台普通的Unix工作站已经可以在价格和性能上完全压制它。PIM机器更是昂贵得离谱——建造一台512处理器的PIM/p需要数千万美元,而同样价格可以购买数百台商用工作站,组成一个更具扩展性的计算集群。
更致命的是,整个软件产业的方向已经改变。1982年,人们相信未来属于专家系统和知识工程。但到1992年,图形用户界面、数据库应用和网络服务成为主流,这些领域需要的不是逻辑推理,而是高速的数值计算、图形渲染和数据吞吐。专用的推理机器在这里毫无优势。
失败的解剖
第五代计算机项目的失败,远比技术路线错误更加复杂。它是一系列战略误判的叠加,是一个时代的野心与另一个时代的现实之间的碰撞。
第一个误判是对并行计算成熟度的过度乐观。1980年代初,并行计算仍处于实验阶段,没有人知道如何有效地为大规模并行机器编程。ICOT团队试图用KL1解决这个问题,但KL1的学习曲线极其陡峭,而且缺乏与主流软件生态的兼容性。结果是,即使在项目内部,能够熟练使用这套技术的专家也寥寥无几。
第二个误判是对专用硬件价值的过高估计。PSI和PIM机器采用了大量专用设计来优化Prolog执行,但这些设计带来的性能优势很快被商用处理器的摩尔定律式进步所抵消。到1990年代中期,一台高端RISC工作站在Prolog基准测试上已经可以匹敌甚至超越昂贵的PSI-II。专用机器唯一的出路是保持一代以上的性能领先,而这在摩尔定律时代几乎不可能。
第三个误判是对软件产业演化方向的判断失误。1982年,日本方面相信知识工程和专家系统将是软件产业的主流方向。但现实走向了完全不同的道路:PC的普及创造了对个人生产力工具的需求,图形用户界面改变了人机交互的方式,关系数据库成为企业信息系统的核心。在这些领域,逻辑编程几乎没有用武之地。
第四个误判是对技术生态开放性的忽视。整个ICOT技术栈形成了一个封闭的世界:KL1语言只能在ICOT的机器上运行,ICOT的机器只能运行KL1程序。这切断了与全球软件社区的任何可能联系,使得ICOT技术无法从外部创新中受益,也无法影响外部的发展方向。
第五个误判是对市场需求的时间窗口判断失误。1982年设想的那些应用——语音识别、机器翻译、自然语言理解——在技术上确实具有巨大的市场潜力,但它们要到2010年代才真正成熟。日本人在正确的问题上提前三十年出发,却因此错过了沿途真正重要的东西。
废墟中的遗产
但将第五代计算机项目完全视为失败是不公平的。从技术和人才的角度看,它留下了深刻的遗产。
在并行计算领域,ICOT的工作具有开创性意义。KL1语言中的许多设计理念——无共享状态、消息传递、进程间通信——在几十年后成为主流并行编程范式的基础。Go语言的goroutine和channel机制,Erlang语言的actor模型,都可以看到GHC/KL1的影子。ICOT对并行符号计算的探索,为后来的并行AI系统铺平了道路。
在逻辑编程领域,第五代计划极大地推动了Prolog及相关技术的研究。ICOT开发的编译器优化技术、抽象解释方法、约束求解算法,至今仍是学术研究的重要参考。许多在项目中工作的年轻研究员后来成为日本计算机科学界的中坚力量,在学术界和产业界持续发挥着影响。
在知识表示和推理领域,ICOT开发的KAPPA系统、QUIXOTE语言等成果,虽然未能商业化,但为后来的知识图谱和语义网技术提供了重要的技术借鉴。项目中的定理证明器MGTP、约束逻辑编程系统GDCC等工具,在学术圈内获得了认可和应用。
更重要的是,第五代计划改变了日本计算机研究的生态。项目吸引了大量优秀人才进入AI和先进计算领域,为日本在这些领域培养了整整一代研究者。项目建立的国际合作网络,使日本计算机科学界与全球社区的联系更加紧密。
从国际视角看,第五代计划的影响更加深远。它直接刺激了美国和欧洲对AI研究的投资,催生了MCC、DARPA战略计算计划、阿尔维计划、ESPRIT计划等一系列重大研究倡议。这些投资虽然也未能实现当初的宏大愿景,但培养了大量人才,积累了大量技术,为后来的AI复兴奠定了基础。
未曾到来的平行未来
如果第五代计算机计划在1990年代成功实现其目标,今天的世界会是什么样子?
在这样一个平行未来中,自然语言处理可能在1990年代就达到了实用水平。人们可以对着计算机说出完整的句子,机器能够理解语义、处理歧义、进行推理。语音识别不再需要预先训练特定说话人的声音模型,而是能够理解任何人的发音。机器翻译的质量达到了人工翻译的八成水准,不再是蹩脚的词语替换。
在这个平行未来中,专家系统可能成为企业信息系统的主流架构。医生使用诊断支持系统,工程师使用设计辅助工具,律师使用案例分析平台——所有这些系统都建立在海量知识库和高效推理引擎之上。知识工程师成为一种受尊敬的职业,负责将人类专家的知识编码进机器可理解的形式。
在这个平行未来中,日本可能在信息产业占据了与美国平起平坐的地位。富士通、日立、NEC的推理机器与IBM的大型机分庭抗礼,日本的AI软件出口成为新的经济支柱,东京成为与硅谷并列的全球科技创新中心。
但这只是一个美丽的幻象。真正的问题在于:即使第五代计算机的技术路线完全成功,它能否阻止互联网和PC革命的到来?答案几乎肯定是否定的。廉价、开放、可扩展的通用计算平台,始终会比昂贵、封闭、专用的系统更具生命力。日本试图通过顶层设计来预测和塑造未来,但技术演进的方向从来不是由单一计划决定的。
技术史上的错位
第五代计算机项目的失败,不是技术能力的失败,而是战略判断的失败。日本人在正确的问题上过早出发,却在错误的技术路径上走到了尽头。
他们正确地预见到知识处理将成为计算机的核心功能,但错误地认为这需要全新的机器架构。实际上,摩尔定律和算法进步使得通用处理器逐渐获得了处理符号计算的能力,专用硬件的优势被不断侵蚀。
他们正确地预见到并行计算的重要性,但错误地选择了并行逻辑编程作为切入点。实际上,数据并行和数值计算并行比符号并行更容易实现和优化,前者成为高性能计算的主流,后者至今仍面临编程模型的挑战。
他们正确地预见到自然语言和语音交互的价值,但错误地认为硬件性能是主要瓶颈。实际上,这些问题的核心在于算法和理解——即使拥有无限的硬件资源,没有正确的算法和模型,机器仍然无法真正理解人类语言。
他们正确地预见到知识工程的战略意义,但错误地低估了知识获取的难度。建立和维护一个大型知识库,需要大量的人工劳动和持续的更新——这不是硬件问题,而是方法论和组织问题。
这些错位不是日本独有的问题。在同一时期的美国,Lisp机器厂商也经历了类似的失败,专家系统在第一次AI寒冬中大量破产,自然语言处理的进展远低于预期。日本只是将这些误判集中在一个国家级项目中,因此失败也更加壮观。
最后的守夜人
今天,PIM/p和PIM/m被保存在东京国立科学博物馆。这些曾经承载着一个国家技术雄心的机器,如今静静地躺在玻璃展柜中,成为计算史上的一段注脚。它们的处理器不再运行推理任务,它们的知识库不再回答问题,它们只是在沉默中注视着智能手机和云计算的时代。
但它们的故事值得被记住。不仅作为一次失败的国家工程,更作为技术史上一次勇敢的冒险。那些在东京摩天楼上度过的十六小时工作日,那些在蓝图和代码中倾注的才华与激情,那些对未来的憧憬和对西方霸权的不甘——这些都是真实存在的,即使它们最终化为废铁。
渊一博在项目结束后不久退休,很少在公开场合谈论这段经历。他在接受采访时曾说,他从不后悔自己的选择。即使项目未能实现商业成功,但它证明了日本有能力进行原创性的计算机研究,有能力提出自己的技术愿景,有能力在完全陌生的领域开辟新路。
这种精神,或许比任何具体的成果都更加珍贵。在计算技术的历史长河中,第五代计算机项目是一座沉默的灯塔,照亮着野心与现实的边界,提醒着后人:技术进步从来不是直线前进的,每一个突破都需要无数先行者的探索和牺牲。
当我们今天站在人工智能新纪元的门槛上,回望这段尘封的历史,或许能够获得一些启示。深度学习和神经网络的崛起,是否也是某种"第五代"式的豪赌?专用的AI加速芯片,是否会重蹈专用推理机器的覆辙?当前AI技术的狂热炒作,是否也包含着类似1980年代的盲目乐观?
这些问题没有简单的答案。但至少,东京塔下那群孤独的守望者已经用他们的经历告诉我们:在技术的征途上,失败不是终点,而是另一条道路的起点。那些埋葬在博物馆里的钢铁幽灵,仍在以某种方式注视着我们,提醒着我们,等待着下一个敢于梦想的人。
参考资料
- Moto-Oka, T. (Ed.). (1982). Fifth Generation Computer Systems. North-Holland Publishing Company.
- Feigenbaum, E. A., & McCorduck, P. (1983). The Fifth Generation: Artificial Intelligence and Japan’s Computer Challenge to the World. Addison-Wesley.
- Fuchi, K. (1992). Aiming for Knowledge Information Processing Systems. Proceedings of the International Conference on Fifth Generation Computer Systems.
- Uchida, S., & Taki, K. (1992). Overview of the Parallel Inference Machine Architecture. Proceedings of the International Conference on Fifth Generation Computer Systems.
- Tick, E., & Ichikawa, H. (1993). A Retrospective and Prospects of the Fifth Generation Computer Systems Project. Journal of Information Processing.
- Shapiro, E. (1989). The family of concurrent logic programming languages. ACM Computing Surveys.
- Shapiro, E., & Takeuchi, A. (1983). Object oriented programming in Concurrent Prolog. New Generation Computing.
- Chikayama, T. (1992). Overview of the Parallel Inference Machine Operating System (PIMOS). Proceedings of the International Conference on Fifth Generation Computer Systems.
- Murakami, M., et al. (1992). Architecture and Implementation of PIM/m. Proceedings of the International Conference on Fifth Generation Computer Systems.
- Institute for New Generation Computer Technology (ICOT). (1992). Fifth Generation Computer Systems 1992, Volumes 1-3. ICOT.
- National Museum of Nature and Science, Japan. (n.d.). Fifth Generation Computer Project Exhibition.
- Stanford University Libraries. (n.d.). Japanese National Fifth Generation Project Archives.
- Association for Computing Machinery. (1993). Appraisal at ICOT of Parallel Processing Research. ACM Digital Library.
- Garvey, S. (2019). Artificial Intelligence and Japan’s Fifth Generation. Stanford University.
- New York Times. (1992, June 5). ‘Fifth Generation’ Became Japan’s Lost Generation.
- Time Magazine. (1983, August 1). Computers: Finishing First with the Fifth.